Panda api 接口文档工具使用说明
Panda api是一款接口设计工具,它能够生成文档、提供接口模拟服务(在你没写任何代码之前)、自动测试后端接口,有效提升项目的开发效率和质量。Talk is cheap, Show you my code.。我们直接从一个例子开始了解他吧。
简易快速入门
安装Panda api
首先,下载对应系统的安装包,安装Panda api
下载解压缩后,双击install开头的执行文件,就可以完成安装。
安装完成后会显示:
Congratulations!
Panda api install done!
You can run pana command in your api docs folder now.
恭喜,已安装完成,你已经可以使用panda api命令了,试一试,检查是否安装成功:
panda -V
// 输出:
basic 0.1.0
如果命令没有生效,那么如果用的是bash,在终端执行命令:souce ~/.bashrc,如果是zsh,那么在终端执行souce ~/zshrc。
或者关闭终端,重新打开一个终端再执行就可以了。
定义一个用户操作的接口文档
我们创建一个目录,起名为api_docs(你也可以起你想要的名字),然后再这个目录中创建auth.json5文件,然后敲上下面的代码
{
name:"用户",
desc:"用户登录系统、退出登录系统",
order:1,
apis:
[{
name:"用户登录",
desc:"用户登录成功,接口会返回一个token",
method: "POST",
url:"/login/",
body_mode:"json",
body:{
username:{name:"用户名"},
password:{name:"用户登录密码"}
},
response:{
code:{name:"返回结果的代码", type:"int", desc:"登录成功只返回1"},
msg:{name:"登录成功返回消息", type:"string", desc:"通常返回都是空"},
token:{name:"登录成功返回的用户token", type:"string", required:false}
},
test_data:[
{
body:{username:"edison", password:"123"},
response:{code:-1, msg:"密码输入不正确"}
},
{
body:{username:"lily", password:"123"},
response:{code:-2, msg:"用户名不存在"}
},
{
body:{username:"root", password:"123"},
response:{code:1, msg:"登录成功", token:"5lCadRru(ADn2IE!$LV%x%JF3JNmz*Nf5nFieUG!r((&esi2CLI$jb!227Lh"}
},
{
body:{username:"lily"},
response:{code:-1, msg:"密码是必填的"}
},
{
body:{password:"123"},
response:{code:-1, msg:"用户名是必填的"}
}
]
},
{
name:"用户退出登录",
method:"GET",
url:"/logout/",
query:{
id:{name:"用户id", type:"int"},
username:{name:"用户名"}
},
response:{
code:{name:"返回结果的代码", type:"int", desc:"退出成功只返回1"},
msg:{name:"退出操作返回消息", type:"string", desc:"通常返回都是空"}
},
test_data:[
{
query:{id:1, username:"root"},
response:{code:1, msg:"退出成功"}
},
{
query:{id:3, username:"lily"},
response:{code:-1, msg:"用户名和id不匹配"}
},
{
response:{code:-1, msg:"必须填写用户名id和用户名"}
}
]
}
]}
我们保存好这个文档,在api_docs目录下,运行命令 panda,就会运行起接口文档服务,
我们就可以在浏览器中输入网址 http://localhost:9000来访问这个文档了。
如果遇到报错,1 请确认是否是在文档目录api_docs/下运行命令;2 如果是端口冲突,可以自行更换端口panda -p 9002,那么你接下来的访问都是http://localhost:9002地址;
在浏览器打开页面,你将看到下面的页面: 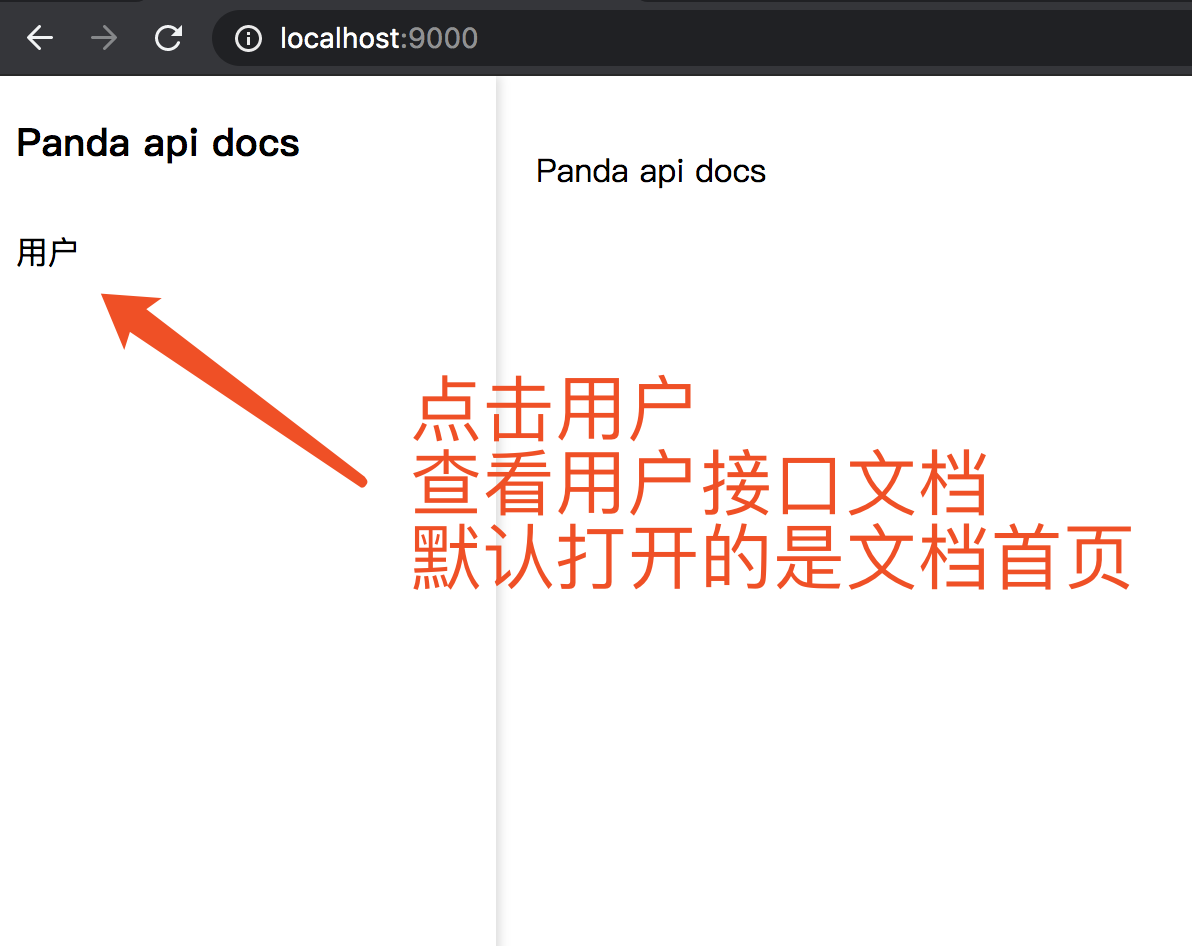 然后点击用户看用户的接口文档
然后点击用户看用户的接口文档 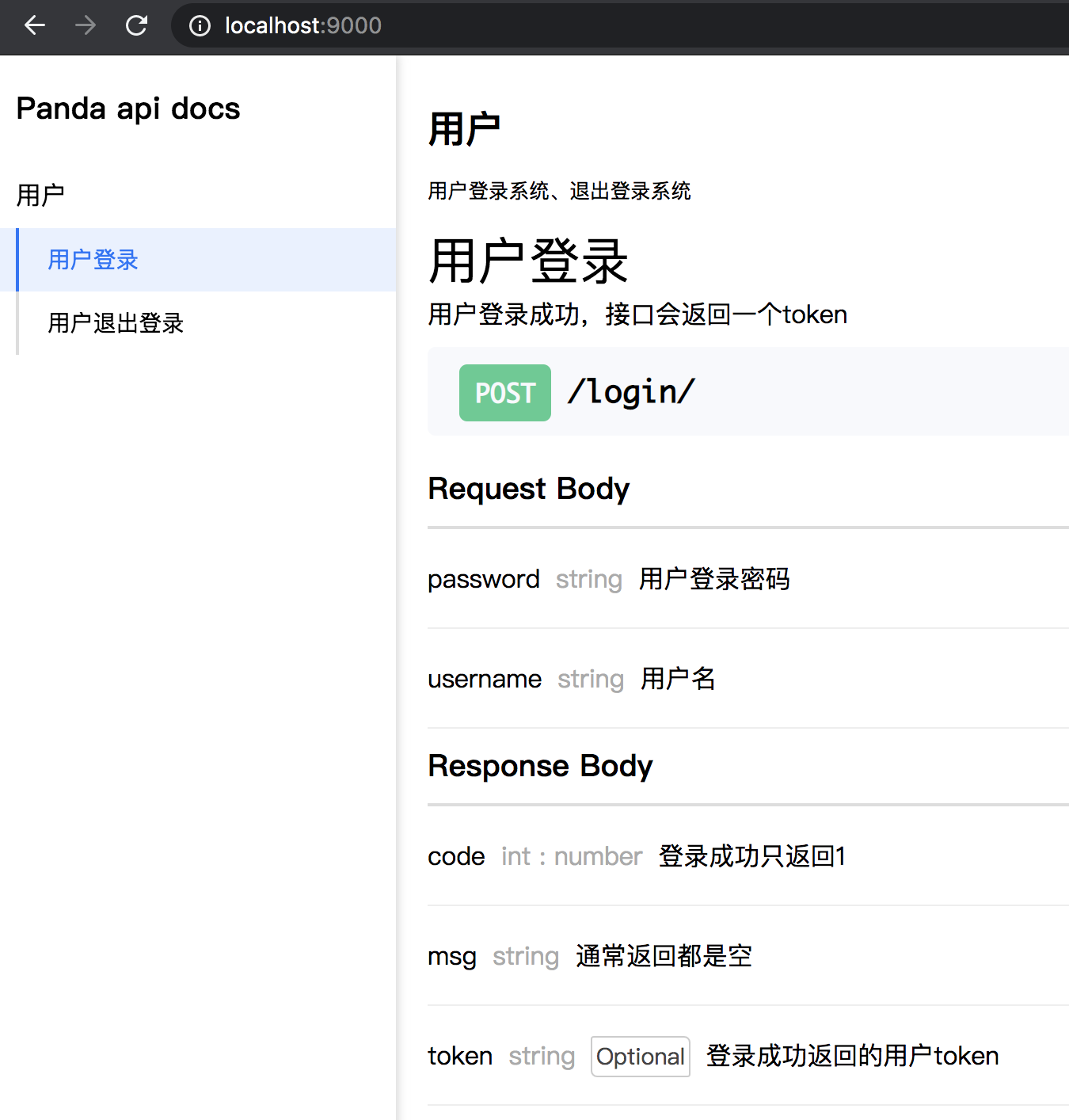
✌️耶~!我们拥有了可以在线浏览的接口文档啦!O(∩_∩)O哈哈~!
继续还有更强大的
Panda api可以为前端提供请求服务
我们的Panda-api或已经开始为我们的前端提供了接口服务,我们的前端开发人员,或者我们用postman就可以测试请求用户登录接口,也就是用POST方法,请求 http://localhost:9000/login/ 这个地址。提交的body参数就是username和password。
我们使用/login/接口的test_data第一个元素的body值提交,提交post请求接口/login/,body为:
{"username":"edison", "password":"123"}
我们会得到返回结果
{"code":-1, "msg":"密码输入不正确"}
当我们提交post请求,body为:
{"username":"lily", "password":"123"}
我们会得到返回结果
{"code":-2, "msg":"用户名不存在"}
当我们提交post请求,body为:
{"username":"root", "password":"123"}
我们会得到返回结果
{"code":1, "msg":"登录成功", "token":"5lCadRru(ADn2IE!$LV%x%JF3JNmz*Nf5nFieUG!r((&esi2CLI$jb!227Lh"}
当我们提交post请求,body为:
{"username":"lily"}
我们会得到返回结果
{"code": -1,"msg": "密码是必填的"}
当我们提交post请求,body为:
{"password":"123"}
我们会得到返回结果
{"code": -1,"msg": "用户名是必填的"}
注意到没,我们请求的参数和返回结果,就是我们在test_data里面设置的数据集,这个数据集中body和response是一一对应的,
我们前端就可以使用这个数据集进行开发了,测试前端请求和返回的各种不同类型的状态,以及各种各样我们想要的特殊情况,我们还可以继续往里面增加各种测试数据。
注意: 在test_data中的数据匹配规则规则是,从列表第一条数据按顺序往后匹配的,只要前面的数据匹配了,就立即返回。
Panda api 自动支持mock
当然,Panda api也是支持mock数据的,如果你请求的数据不是test_data数据集里面的数据,你将会得到系统自动mock数据的返回。
我们提交post请求,body为:
{"username":"hello", "password":"123"}
因为没有test_data数据匹配,就会得到mock数据返回结果
{
"code": -5217373750860980588,
"msg": "3^m)v8TbukaRauosV"
}
// 或者
{
"code": 1157384092555109544,
"msg": "hJLaTF&75tPnsZ%wSjUp1qr~QwH",
"token": "1JOU0s)sunBOM5!Lo4Ao"
}
我们可以不停的就用这个数据请求,会不停的得到随机mock的数据,这得益于我们已经定义好了良好的request请求数据文档和response返回数据文档。不过这样的mock数据稍微有点和我们想要的有点差距,我们来改进一下 /login/ 接口的 response字段定义
// 这是 原始 response
response:{
code:{name:"返回结果的代码", type:"int", desc:"登录成功只返回1"},
msg:{name:"登录成功返回消息", type:"string", desc:"通常返回都是空"},
token:{name:"登录成功返回的用户token", type:"string", required:false}
},
// 改为
response:{
code:{name:"返回结果的代码", type:"int", desc:"登录成功返回1, 登录失败返回-1", enum:[-1, 1]},
msg:{name:"登录成功返回消息", type:"csentence", desc:"通常返回都是空"},
token:{name:"登录成功返回的用户token", type:"string", required:false, length:60}
},
保存文件后,直接继续用不在test_data里面的数据请求接口/login/,(当保存好文档,Panda api会自动更新文档数据,瞬间完成,不用手动重启)
{"username":"hello", "password":"123"}
就会得到mock返回结果
{
"code": 1,
"msg": "认管原务给接办例热。"
}
// 或者
{
"code": -1,
"msg": "权世间素调条中儿白工造种高厂节看县。",
"token": "Vr&B%waOl6i(Uy(o~WWBnA@#80p6^ZnFAW24uYe&dH4))xmT@dz3^%&SWKBY"
}
怎么样,更符合我们的需要了吧。
我们对code字段,增加了enum属性enum:[-1, 1],限定了code的值范围只能是-1或者是1里面的其中一个。
把msg字段的类型type从string改为了csentence,csentence是string的一个子集,表示中文句子,csentence太长太难写了,你也可以使用它的简写cs是一样的
限定了token字段的长度为60
test_data中的字段mock
在test_data中,有一组数据是这样的:
{
test_data:[
...
{
body:{username:"root", password:"123"},
response:{code:1, msg:"登录成功", token:"5lCadRru(ADn2IE!$LV%x%JF3JNmz*Nf5nFieUG!r((&esi2CLI$jb!227Lh"}
}
...
]
},
这个是一个登陆成功的测试数据,他已经可以满足满足我们前端开发的需求,但是稍微有一点不完美,就是正常情况下,我们每次登陆返回的token应该是动态随机生成的,而不应该是固定的,我们需要对token字段使用mock,所以我们改一下这一组数据:
{
test_data:[
...
{
body:{username:"root", password:"123"},
response:{code:1, msg:"登录成功", token:{$mock:true, required:true}}
}
...
]
},
保存文档,然后请求接口/login/,请求body数据为{username:"root", password:"123"},你就会得到动态的符合要求的token。
这里修改中,我们把token原设置的字符串给为了一个对象{$mock:true},表示这个字段开启mock数据生成,这要求token字段必须在接口response文档中中有对应的定义,否则这个字段就会被忽略。然后在接口response中token字段是可有可无的required:false,生成的mock有时候回有,有时候没有,但是在我们指定了用户名密码是登录成功的状态下,token是必须有的,所以我们重写了token字段的required:true,这样就每次请求,一定有token返回。
在token:{$mock:true, required:true}这里,你可以重写你想要的任何token字段的属性。
下面我们把这个接口文档的每一个部分都详细说明一下
接口文档的根字段
我们定义了一个用户的接口文档,在接口文档的最根节点有三个字段:
name:"用户操作", /* 当前接口文档名称 */
desc:"用户登录系统、退出登录系统", /* 当前接口文档描述说明 */
order:1, /* 表示有多个文档时,当前文档在列表中的排序 */
apis:[...] /* 当前接口文档的接口列表 */
在这个用户操作的接口文档中,我们在apis这个接口列表里面定义了2个接口,用户登录接口和用户退出登录接口,我们先看用户登录接口
接口的完整字段
apis:[{
name:"用户登录", /* 接口的名称 */
desc:"用户登录成功,接口会返回一个token", /* 接口的描述说明 (可选),不写时默认为空 */
method: "POST", /* 接口的请求方法 (可选) 不写时默认是GET */
url:"/login/", /* 接口请求的url地址 */
url_param:"", /* url参数说明 例如 /user/{name}/ 对name字段进行描述 */
auth:false, /* 是否需要登录, 默认为false */
body_mode:"json", /* 请求的数据格式 */
body:{ /* post 请求的 body 字段说明, */
username:{name:"用户名"},
password:{name:"用户登录密码"}
},
query:null, /* url上的query参数(可选) 比如aaa=3&bbb=4 不填写时默认为空 */
request_headers:null, /* 请求头的参数要求(可选),通常用于定义多版本接口 默认为空 */
response_headeres:null, /* 设置返回值的头的字段值(可选),例如:返回状态码、content_type等 */
response:{ // 请求成功后的返回数据结构和字段
code:{name:"返回结果的代码", type:"int", desc:"登录成功只返回1", enum:[-1, 1]},// 设置了字段类型是int, 增加了code的值范围 是-1或1
msg:{name:"登录成功返回消息", type:"csentence", desc:"通常返回都是空"}, // 字段类型为 csentence, 表示中文句子,也可以使用简写cs
token:{name:"登录成功返回的用户token", type:"string", required:false, length:60} // 限定token的length长度为60
},
test_data:[...] // 前端请求和返回的测试用例数据
}]
method
其中当请求method是POST的时候,body_mode和body字段设置了才会有效,当请求method是GET的时候,对应的字段是query。
method可以设置为单个方法,例如:method:"POST" 或者 method:"GET";
method还支持多方法,例如:method:["GET", "POST", "PUT"]
还可以直接设置method 支持所有方法:method:"*"
目前method一共支持的方法有:POST、GET、PUT、DELETE、OPTIONS、PATCH、HEAD
- GET:读取(Read)
- POST:新建,新增(Create, Add)
- PUT:更新(Update)
- PATCH:更新(Update),通常是部分更新
- DELETE:删除(Delete)
body 字段
body表示post的请求body,因为我们定义body_mode是json,因此他必须提交json格式的数据。 body中的第一个字段username的属性是{name:"用户名"}, 这个属性的完整写法是
username:{
name:"用户名", /* 字段的名称 */
desc:"用户名的描述", /* 字段的描述说明 */
type:"string", /* 字段的类型, (可选) 不填写时默认是string */
required:true, /* 字段是否必填,(可选) 不填写的时候默认是必填 */
default:null, /* 字段的默认值,(可选) 不填写时默认是空 */
value:null, /* 字段的固定值,(可选) 不填写时默认是空 */
enum:[] /* 字段的枚举值,(可选) 表示字段只能从这几个字段中有值,比如["edison","lemon","jay"], 那么username只能是这3个值中的一个 */
}
enum有两种写法,一种直接就是值: enum:[-1, 1],或者是值加值的描述 $enum:[[-1,"失败"], [1, "成功"]],注意$enum前面多了一个$美元符号,表示后面的元素是以数组形式表现,元素的第一个是值,第二个是值的描述,这是简写的语法优化。 两种写法得到的结果是一样的,值只会从-1和1中选取。增加$enum方式的目的是为了方便以后值的阅读和维护,我们经常时间长了会忘记每一个枚举值的作用。
当我们不写desc属性时,默认为空,不写required属性时,默认为true, 也就是这个字段是必填的。
type 字段的类型说明
type 字段基础类型一共有这几种
- string 字符串 "aaa"
- number 数字 1、2
- bool 布尔值 true、false
- object 对象 {}
- array 数组 []
除了基础类型,还有更好用的子类型 以及属性的说明 更多在
request_headers
表示请求头的参数要求,一旦定义了,那么请求头上必须含有这些参数和值,才可以访问该接口,否则就不能访问。通常用于接口多版本的定义,例如:
request_headers:{
Accept: vnd.example-com.foo+json; version=1.0 // 表示1.0版本的接口
}
request_headers:{
Accept: vnd.example-com.foo+json; version=1.1 // 表示1.1版本的接口
}
request_headers:{
Accept: vnd.example-com.foo+json; version=2.0 // 表示2.0版本的接口
}
如果这么定义后,不同的接口,就算是同一个url,同一个请求方法,但是因为request_headers不一样,就会路由到不同的接口上。
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services)
response_headers
设定返回结果的response,通常用于定义返回状态码,修改content-type等。例如:
response_headers:{
status_code: 202, // 异步接口
}
// 请求接口后,服务器会返回
HTTP/1.1 202 Accepted
Location: /proccese/status/
这是一个异步接口,服务器返回202, 202 Accepted告诉客户端,请求已经接受,但还没有处理,可以去Location字段查询进展。
除了上面的头信息,服务器的回应如果有数据体,可以返回一些有效信息(比如任务完成的估计时间、当前状态等等)。
默认服务器返回的content-type都是application/json,我们可以设定返回的内容类型,例如:
response_headers:{
"content-type": "image/png", // 返回一张图片
}
response
response表示请求后返回的结果字段说明,我们也可以使用response中某个字段的值为请求body或query中的值。例如:
...
body:{
username:{name:"用户名"},
password:{name:"密码"},
},
response:{
code:{name:"返回结果的代码", type:"int", desc:"登录成功", $enum:[[-1, "失败"], [1, "成功"]]},
msg:{name:"登录成功返回消息"},
username:{name:"登录成功的用户名", $value:"$body/username"}
},
...
通过设置response中字段的$value属性,然后调用$body中的username字段的提交值。如果要获取上传文件的url则需要再最后增加:url属性。例如:$value:"$body/file:url"
test_data
test_data是非常强大和方便的一个功能,表示前端请求的数据和对应返回的数据集,我们定义好了这个数据集,系统才会接收对应的数据请求,然后返回对应的数据。里面的字段就可以根据真实情况,自己按要求去定义和模拟就好了。
test_data里面完整的有:
{
method:"", /* 请求方法 */
body: {...}, /* request body 请求值, 只在POST请求是才有 (可选) */
query:{...}, /* url query 请求值 在POST和GET中都可以有 (可选) */
form_data:{...} /* 请求的form_data */
url:"/post/10/", /* 在接口url是一个正则匹配时,test_data可以指定具体的url匹配 */
response:{...} /* 返回结果 */
}
用户退出登录接口
我们把用户退出登录接口/logout/的response 的字段也进行了调整,方便mock出更好看的数据。
{
name:"用户退出登录",
method:"GET", // 使用GET方法请求
url:"/logout/",
query:{ // GET 方法请求的query参数的数据结构字段说明
id:{name:"用户id", type:"int"},
username:{name:"用户名"}
},
response:{
code:{name:"返回结果的代码", type:"int", desc:"登录成功只返回1", enum:[-1, 1]},
msg:{name:"登录成功返回消息", type:"csentence", desc:"通常返回都是空"}
},
test_data:[
{
query:{id:1, username:"root"},
response:{code:1, msg:"退出成功"}
},
{
query:{id:3, username:"lily"},
response:{code:-1, msg:"用户名和id不匹配"}
},
{
response:{code:-1, msg:"必须填写用户名id和用户名"}
}
]
}
这里因为是为了模拟GET请求中的query参数,所以可以加了username和id字段。我们可以看到,当请求method是GET的时候,我们的query参数就要放到query字段中,当然query这个字段的参数在POST请求时也是有效的,你可以同时有body参数和query参数
在退出登录接口中,因为请求方法是GET, 所以请求参数放到了query中
query:{
id:{name:"用户id"},
username:{name:"用户名"}
},
对应的test_data里面,请求的参数也是query和response对应。
我们提交GET请求接口/logout/,query为:
{"id":1, "username":"root"}
就会得到response结果
{"code":1, "msg":"退出成功"}
我们提交GET请求接口/logout/,query为空,啥也不传,请求接口,就会得到response结果
{"code":-1, "msg":"必须填写用户名id和用户名"}
我们提交GET请求接口/logout/,query为
{"id":3, "username":"lily"}
就会得到response结果
{"code":-1, "msg":"用户名和id不匹配"}
我们提交GET请求接口/logout/,query为不是test_data列表里面的值,那么就会得到mock结果
{"id":22, "username":"lemon"}
就会得到response mock 结果
{
"code": 1,
"msg": "化认九全准问可信须边切步和太常八权光更书府深始什委设省如消确约领须划存规到方任新数者就世响方许,"
}
// 或者
{
"code": -1,
"msg": "教文片场必非却电影万些人社进养身新带就选员民先已拉走温件意如做此然价亲种标即格先了江,"
}
注意: 在test_data中有一个数据是没有query参数限制的,这种限制越少的参数要往后面放,test_data的匹配规则是,从列表第一条数据按顺序往后匹配的,只要前面的数据匹配了,就立即返回。
设置项目的概要
创建文件_settings.json5,敲上下面的内容。(注意,文件名开头有一个下划线,主要是为了把他和正常的接口文档区分开)
{
project_name: "Panda Api", /* 项目名称 */
project_desc: "Panda Api is a simple api manage tool" /* 项目简述 */
}
设置项目首页说明
创建文件 README.md,
# Hello Panda api
大家好,我是一个项目说明文档
整个项目的全部desc字段和 README.md文件里面的内容都是支持markdown语法的。
原生json5语法是字符串换行的,也支持//注释和/ 注释 /, 你可以这么写:
"desc":"##说明文档
1 aaaa
2 bbbbb
3 ccccc
"
列表和对象
获取文章列表接口
{
name:"文章列表",
method:"GET",
url:"/post/star/list/",
query:{
page:{name:"分页", type:"number"}
},
response:{
total_page: {name:"总页数", type:"number"},
total_count: {name:"总记录数", type:"number"},
current_page: {name:"当前页码", type:"number"},
result:
[{
$name:"文章列表",
$desc:"只包含用户点赞过的文章列表",
id: {name:"用户id", type:"number"},
title: {name:"文章标题"},
category: {
$name:"文章所属分类",
$desc:"这里为了体现对象,所以就特意把文章分类用一个对象来表示",
id:{name:"分类id", type:"number"},
name:{name:"分类名称", type:"string"}
},
content: {name:"文章内容"},
created: {name:"文章创建时间", type:"number"}
}]
}
}
这个例子中,response返回的结果中,result字段,还有一点特殊,他是一个列表,然后列表里面有一个对象,他表示result的类型是array,然后里面的那个对象描述的是array中的数据的展现类型,字段有哪些。
result中的最开头 $name 字段和$desc字段是用来描述result字段的名称和描述。因为为了防止和常规字段冲突,所以在前面加了$减号,
系统会根据[]自动识别result是一个数组,而且人阅读起来也很友好,因此不再需要标注类型
category字段的类型是一个对象object, 里面有两个属性id和name,分别表示分类的id和分类的名称。同样的$name, $desc是用来描述category这个字段的。系统也会自动识别出object对象,因此不需要人工标注类型
注意事项
如果不同的接口,同一个url, 但是请求方法不同,有GET,有POST是允许的。你可以为每一种方法定义不同的接口
如果不同的接口,同一个url, 请求方法也相同,都是GET或者都是POST,那么系统会判定,只允许一个,前面的会被后面的覆盖。
教程中的代码在这里: https://github.com/arlicle/panda-api-examples/tree/master/simple
结尾
至此,我们的建议教学就结束了,可以试着找一个以前的项目或者新项目,开始写自己的接口文档,遇到有任何的问题或者意见建议,欢迎和我讨论。
下一篇,开启高级教学,一些复杂的用法,以及代码和数据的重用,让我们更简单快速的维护接口文档。
2020-03-02 08:34